NCD-03 in the Nutanix Cluster Design Fundamentals series, baselined to AOS 7.3, AHV 10.3, and Prism Central 7.3. This article takes apart the Distributed Storage Fabric: the services that run inside every Controller VM, the structures your data is actually stored in, the write path and the read path step by step, how metadata stays consistent at scale, and how replication and integrity work underneath every container you create. NCD-01 covered fault domains and the cluster math. NCD-02 covered the network those services talk over. This one is the storage engine itself.
Sources: the Nutanix Cloud Bible (Book of AOS, Basics: Cluster Components, Data I/O Path, Data Resilience and HA), portal.nutanix.com AOS Storage documentation and the Definitive Guide to AOS Storage, and the Nutanix.dev distributed storage articles. The legacy AOS Storage Bible page was split on April 23 2026 into the Data I/O Path, Data Efficiency, and Data Resilience books. The technical claims and version sensitive values below were checked against those sources. Compression, deduplication, and erasure coding mechanics are named here but covered in depth in NCD-04.
FoundationWhat the Distributed Storage Fabric is
The Distributed Storage Fabric (DSF) is the software defined storage layer of AOS. It pools the physical drives across every node into one logical capacity and presents that capacity to the hypervisor as if it were a centralized array. Across supported hypervisors, AOS exposes storage through the appropriate integration path: AHV accesses storage containers transparently, ESXi sees them as NFS datastores, and Hyper-V sees them as SMB shares. The point for this article is that the hypervisor sees a simple storage target while DSF distributes and protects the data underneath. It does not know or care that the bytes are scattered across a dozen nodes.
The point that gets missed: DSF is not a SAN with the controller moved into software. The controller is not one place. Every node runs its own storage controller, and I/O for a VM is served by the controller on the node that VM runs on. That is the whole design. Centralized presentation, fully distributed execution, and the I/O path stays local to the host whenever it can.
That distributed controller is the Controller VM, the CVM. One per node. It owns the storage devices directly, the hypervisor hands the disk controllers through to it, and every storage service in this article runs inside it. When people say a node, in storage terms they mean the CVM on that node and the drives it owns.
ServicesWhat runs inside the CVM
DSF is not a monolith. It is a set of cooperating services, each with one job, each running on every node and electing a leader where coordination is needed. You will see these names in logs, in NCC output, and in support cases, so learn them now.
| Service | Job | Where it runs |
|---|---|---|
| Stargate | All data I/O. The single point of contact for reads and writes from the hypervisor. Handles replication, the OpLog, the Extent Store, and the cache. | Every node, serving local I/O |
| Cassandra | The distributed metadata store. A heavily modified Apache Cassandra holding the maps of where every piece of data and every replica lives. | Every node, ring structured |
| Medusa | The abstraction layer in front of Cassandra. Stargate and Curator never touch Cassandra directly, they go through Medusa. | Every node |
| Zookeeper | Cluster configuration: hosts, IPs, state. Based on Apache Zookeeper. Elects a leader that handles config writes. | 3 nodes (RF2) or 5 nodes (RF3) |
| Zeus | The access interface to Zookeeper. Config reads and writes go through Zeus. | Every node |
| Curator | Background cluster management through MapReduce. Disk balancing, tier movement (ILM), proactive scrubbing, garbage cleanup. An elected Curator Leader delegates work. | Every node, leader elected |
| Chronos | Takes the jobs a Curator scan produces and schedules and throttles them across nodes so background work does not starve front end I/O. | Every node, master on the Curator Leader node |
| Pithos | vDisk configuration data. Built on top of Cassandra. | Every node |
| Cerebro | Replication and DR: snapshot scheduling, replication to remote sites, failover. Relevant in NCD-08, listed here for completeness. | Every node, leader elected |
| Genesis | The process manager. Starts, stops, and restarts services on a node. Runs independently of cluster state, which is why it works before the cluster is even formed. | Every node |
| Prism | The management gateway: HTML5 UI, nCLI, REST API. Elects a leader, forwards requests to it through iptables, so any CVM IP reaches Prism. | Every node, leader elected |
The dependency chain is worth holding in your head. Stargate depends on Medusa for metadata and Zeus for configuration. Curator depends on Zeus to check node health and Medusa to read metadata, then issues commands to Stargate based on what its scans find. Cassandra depends on Zeus. Nothing important happens without Zookeeper, which is why its node count is tied to the redundancy of the whole cluster.
MetadataCassandra, Medusa, and strict consistency
Storage metadata has to be right one hundred percent of the time. A storage system that loses track of where a replica lives, or returns a stale map, corrupts data silently. So metadata gets stricter treatment than the data it describes.
Cassandra stores metadata in a ring across all nodes. On a metadata write, the row is written to one node in the ring and replicated to a number of peers. Here is the part that matters: a majority of those nodes must agree before the write commits. That quorum is enforced with the Paxos algorithm. Nutanix uses a heavily modified Cassandra implementation and Paxos based quorum to enforce strict consistency for storage metadata, rather than relying on the eventually consistent usage most people associate with stock Cassandra deployments.
Paxos depends on quorum, a majority of voters agreeing. Odd voter counts are preferred because they give clean majority behavior without spending an extra voter that does not raise failure tolerance. Three voters need two for quorum and tolerate one loss. Five need three and tolerate two. Four still need three for quorum, so a fourth voter adds overhead without improving tolerance over three. For 1N/1D, Nutanix keeps 3 metadata copies and needs 2 of 3 to agree. For full 2N/2D, Nutanix keeps 5 metadata copies and needs 3 of 5. The three node 1N&1D edge case is different: it uses RF3 data, but metadata remains at 3 copies because there are only three nodes to place them. This is also why the full 2N/2D design needs five nodes.
Two terms get confused constantly, and the confusion shows up in design reviews. Replication Factor is the container level data protection setting: RF2 keeps two data copies, RF3 keeps three. Redundancy Factor is the cluster level resiliency setting that drives metadata and configuration placement: in 1N/1D, Nutanix maintains three metadata and configuration copies; in full 2N/2D, it maintains five. The three node 1N&1D mode is the edge case: RF3 data with three metadata copies. They are not the same control, they do not live at the same scope, and a cluster at higher fault tolerance can still host Replication Factor 2 containers. NCD-01 worked through the node count math this drives. The takeaway for storage design: the cluster wide Redundancy Factor sets how many node losses your metadata survives, independent of any one container.
StructuresHow your data is actually laid out
From the hypervisor down to the platter or flash cell, data passes through five nested structures. Knowing them is the difference between reasoning about performance and guessing at it.

| Structure | What it is |
|---|---|
| Storage Pool | A group of physical devices (NVMe, SSD, HDD) spanning every node in the cluster. It grows as the cluster grows. Almost every cluster uses exactly one storage pool. There is rarely a good reason for more. |
| Container | A logical slice of the storage pool that holds vDisks. This is where you set Replication Factor, compression, deduplication, erasure coding, and reservations. Settings are configured on the container and applied per VM or per file. On AHV it is presented transparently through the AHV storage stack. On ESXi it is exposed as an NFS datastore. On Hyper-V it is exposed as an SMB share. |
| vDisk | Any file over 512KB on DSF, including .vmdk and VM hard disk files. A vDisk is logically composed of vBlocks, which together form its block map. |
| vBlock | A 1MB chunk of a vDisk's address space. A 100MB vDisk is 100 vBlocks. vBlock 0 covers bytes 0 to 1MB, and so on. vBlocks map to extents. |
| Extent | A 1MB piece of logically contiguous data. Extents are read, written, and modified at the slice level for granularity, where a slice is a sub region of the extent that gets trimmed into cache based on how much is actually touched. |
| Extent Group | 1MB or 4MB of physically contiguous data, stored as a file on a device owned by the CVM. Extents are distributed across extent groups to stripe data over nodes and disks. The group is 4MB normally and 1MB when deduplication is in play. |
The design consequence of this layout: there is no static binding. A vDisk is not pinned to a disk when it is created or on first write. AOS places each write on the best device available at that moment based on real time performance, utilization, and health across the cluster. Striping happens at the extent level, so a single noisy vDisk spreads its load instead of hammering one spindle. This is why you cannot reason about Nutanix capacity the way you reason about a fixed LUN.
Write pathOpLog, Extent Store, and AES
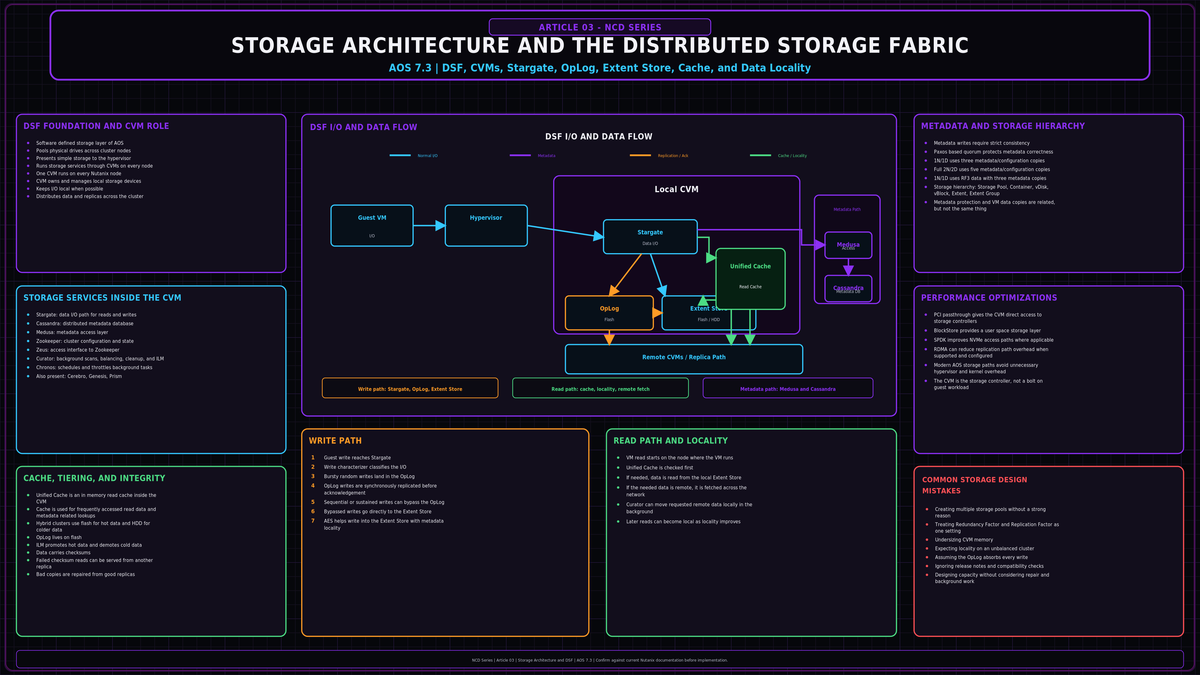
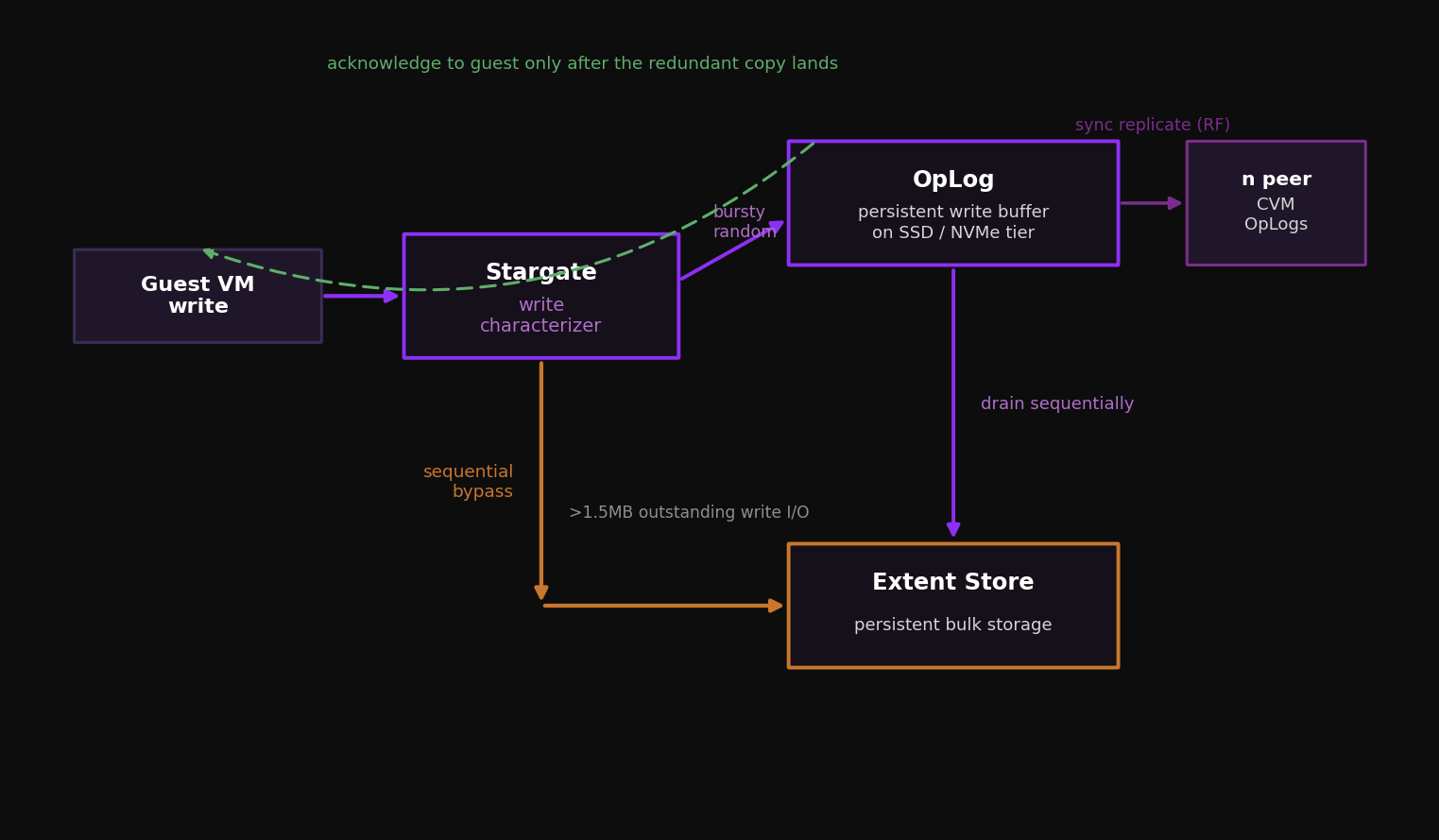
When a write reaches Stargate, a write characterizer decides where it goes. Bursty random writes land in the OpLog. Sustained random and sequential writes go straight to the Extent Store. The split exists because those two profiles want opposite handling.
The OpLog
The OpLog is a persistent write buffer, structured like a filesystem journal. It absorbs bursts of random writes on the fastest tier in the node, coalesces them, then drains them sequentially into the Extent Store. It lives on the SSD or NVMe tier, and every flash device in the node carries a portion of it.
The resilience step is in the write path itself. Before a write is acknowledged back to the guest, the OpLog is synchronously replicated to the OpLog of n other CVMs, where n follows the container Replication Factor. RF2 means one local copy plus one remote, acknowledged once the remote write lands. The peers are chosen dynamically by load, and every CVM's OpLog participates. The guest does not get its acknowledgement until the redundant copy exists. That is how a node can fail mid write without losing the acknowledged data.
A write is treated as sequential once there is more than 1.5MB of outstanding write I/O to a vDisk (Gflag vdisk_distributed_oplog_skip_min_outstanding_write_bytes). Those writes bypass the OpLog and go directly to the Extent Store, because they are already large aligned chunks that gain nothing from coalescing. Large individual I/Os over 64K that do not meet the sequential threshold still go through the OpLog. The OpLog is for absorbing random bursts, not for staging bulk throughput.
The Extent Store
The Extent Store is the persistent bulk storage of AOS. It spans every device tier (NVMe, PCIe SSD, SATA SSD, HDD) and extends as you add devices. Data arrives in it one of two ways: drained from the OpLog, or written directly when it was characterized as sequential. Once data is in the Extent Store, ILM decides which tier it belongs on based on access patterns, access counts, and the weight assigned to each tier.
The Autonomous Extent Store
The Autonomous Extent Store (AES) is the method AOS uses to write into the Extent Store with metadata locality. Instead of every metadata operation traversing the global Cassandra ring, AES keeps a mix of primarily local metadata alongside the global metadata, so sustained writes do not pay the cost of a cluster wide metadata round trip on every operation. Sustained random writes bypass the OpLog and write straight to the Extent Store through AES. Bursty random writes take the normal OpLog path and then drain through AES where possible.
AOS 6.8 added AES Optimized Metadata for all flash and NVMe clusters, and it carries forward into the 7.3 baseline. It batches sustained random writes into fewer metadata transactions, which cuts the number of disk operations needed to persist them. The result is lower CPU per write and higher sustained random write throughput on flash. On hybrid nodes the benefit is smaller, because the HDD tier is the limiter, not metadata transaction count.
Read pathThe Unified Cache and data locality
Reads are served from wherever the data currently is. If it is still in the OpLog and not yet drained, the OpLog answers. Otherwise the read comes from the Extent Store, and the Unified Cache sits in front of that.
The Unified Cache
The Unified Cache is an in memory read cache in the CVM, used for data, metadata, and deduplication fingerprints. On a read miss the data is pulled from the Extent Store and placed into the single touch pool, held in memory under LRU until evicted. A second read promotes it into the multi touch pool, and every later hit in that pool resets its LRU counter and keeps it hot. Data enters the cache at 4K granularity, in real time, with no batch delay.
The Unified Cache size is ((CVM Memory minus 12 GB) times 0.45). A 32GB CVM yields ((32 minus 12) times 0.45) equals 9GB of cache. This is the direct lever between CVM memory sizing and read performance. Starving the CVM of RAM to hand more to guest VMs shrinks the cache and pushes reads down to the Extent Store. Size the CVM for the working set, not the leftovers.
Data locality
A read is initiated on the node where the VM runs. If the local cache or local Extent Store has the data, it is served locally with no network hop. If the only copy lives on a remote node, that copy is fetched across the network once and written locally so subsequent reads stay local. Data follows the VM. Live migrate a VM to another host and its hot data migrates to the new local node over the next reads, restoring locality without any administrator action.
This is why a balanced cluster matters. Locality assumes the working set can sit on the local node's flash. If a host is starved of capacity or its CVM is undersized, locality degrades into constant remote fetches, and the network becomes the bottleneck for something that should never have left the node.
TieringDevices, tiers, and ILM
The tier model depends on what is in the node.
- All flash (all NVMe, all SSD, or mixed flash): the Extent Store is a single flash tier and no tier ILM movement occurs. There is nowhere colder to move data to.
- Optane plus NVMe or SATA SSD: the Optane is Tier 0, the lower flash is Tier 1.
- Hybrid flash plus HDD: flash is Tier 0, HDD is Tier 1, and the OpLog always lives on the flash.
ILM (Intelligent Lifecycle Management) moves data between tiers based on access patterns. Hot data is promoted to the fastest tier, cold data is demoted to make room. Curator drives this in the background, alongside disk balancing, which keeps utilization even across devices and nodes so no single drive becomes a hot spot. None of this is on the front end I/O path. It is background work that Chronos throttles so it does not compete with live workload.
IntegrityChecksums, scrubbing, and the I/O path optimizations
Every piece of data carries a checksum. On every read the checksum is recomputed and compared. If it does not match, the read is satisfied from another replica and the bad copy is replaced. Integrity is not only checked on access. Stargate runs a scrubber that walks the extent groups and validates checksums when disks are not busy, so silent corruption is found before anyone reads the data again. With RF set correctly, a failed checksum is a non event: the cluster has another good copy and repairs itself.
Where the I/O path got faster
Three optimizations sit underneath everything above, and they explain why CVM based storage is not the overhead it looks like on paper:
The takeaway is that the CVM is not a software array bolted on top of the hypervisor's storage stack. On modern hardware it talks to flash and to the network in user space, around the kernel, around the hypervisor.
MistakesThe design mistakes that cost you later
Carving up multiple storage pools
Splitting a cluster into several storage pools to separate workloads is almost always wrong. It fragments capacity, breaks the cluster wide striping that gives DSF its performance, and creates pools that fill independently while others sit empty. Use one storage pool. Separate workloads with containers, which is what containers are for.
Treating Redundancy Factor and Replication Factor as one setting
They are different controls at different scopes. Setting container Replication Factor to 3 does nothing for metadata redundancy if the cluster Redundancy Factor is still 2. A cluster that needs to survive two simultaneous node losses needs Redundancy Factor 3, the node count to back it, and RF3 containers for the data that matters. Decide both, deliberately.
Undersizing CVM memory
The Unified Cache is ((CVM memory minus 12 GB) times 0.45). Trimming CVM RAM to free memory for guests shrinks the read cache directly and pushes reads onto the Extent Store. On read heavy workloads this shows up as latency nobody can explain, because the cause is a sizing decision made months earlier.
Expecting locality on an unbalanced cluster
Data locality only helps when the local node can hold the working set on flash. Mixed node sizes, a capacity starved host, or an undersized CVM all degrade locality into constant remote reads. The fix is balanced node sizing, not more network.
Assuming the OpLog absorbs everything
Sustained and sequential writes deliberately skip the OpLog and go straight to the Extent Store through AES. Sizing the flash tier as though every write stages through the OpLog first misreads the architecture. Bulk write throughput is an Extent Store and tier question, not an OpLog question.
Building even numbered metadata or Zookeeper layouts
Paxos quorum behaves cleanest on an odd voter count, since an even count adds a voter without raising failure tolerance. This is handled for you by the Redundancy Factor and the cluster's own placement, but it is the reason minimum node counts are what they are. Do not fight the odd numbers. NCD-01 has the full node count math.
- DSF is centralized presentation with fully distributed execution. Every node runs a Controller VM that owns its drives and serves local I/O. There is no single controller.
- The service set matters: Stargate handles all I/O, Cassandra holds metadata accessed through Medusa, Zookeeper holds config accessed through Zeus, Curator runs background MapReduce work, Chronos throttles it.
- Metadata uses Paxos for strict consistency across an odd number of nodes. Replication Factor is data copies at the container level. Redundancy Factor is the cluster level setting that drives metadata and configuration placement. They are separate decisions.
- Data nests as storage pool, container, vDisk, vBlock, extent, extent group. There is no static disk binding. Writes go to the best device in real time and stripe across the cluster.
- Bursty random writes stage in the OpLog and replicate synchronously before acknowledgement. Sustained and sequential writes bypass the OpLog and write directly to the Extent Store through AES.
- Reads serve from the Unified Cache or local Extent Store first, and data locality pulls remote copies local on access. Cache size is tied directly to CVM memory.
- Checksums on every read plus a background scrubber make corruption self healing as long as Replication Factor is set correctly.
- Use one storage pool, size CVM memory for the working set, keep node sizing balanced, and set both factors deliberately.